
Nombre de resultats 25
per a C
19/01/2023 - Roskilde
Considerada una de les ciutats més antigues de dinamarca, Roskilde té el Museu dels vaixells vikings, on es poden veure el que queda de cinc vaixells enfonsats al segle XI. Al museu et pots vestir com els vikings de l’època, … Continua llegint →

18/01/2023 - Castell de Frederiksborg
Situat a la població de Hillerod, al nord de Selandia, la més gran de les illes de Dinamarca, el Castell de Frederiksborg es troba a una quarantena de quilòmetres de la capital danesa, i està connectat amb Copenhaguen per tren. … Continua llegint →
17/01/2023 - Copenhaguen
Copenhaguen, amb més d’un milió d’habitants, és la capital de Dinamarca. Situada estratègicament a l’entrada de la mar Bàltica a l’illa de Sjælland, és una ciutat molt tranquil·la, perfecte per perdre’s pels seus carrers i disfrutar dels seus parrcs. La millor … Continua llegint →
16/01/2023 - Dinamarca 2022
Reprenem els viatges d’estiu, aquest 2022 hem visitat el país de l’escriptor Hans Christian Andersen El passat estiu vam visitar un país que feia temps que li teníem ganes, Dinamarca. Tot i que ens vam perdre molts llocs xulos, vam … Continua llegint →
28/07/2019 - 2019#20,21,22 Readings of the week
I’ve been pretty busy lately, and although reading doesn’t stop, my writing sometimes takes a hiatus.
NOTE: The themes are varied, and some links below are affiliate links. Data engineering, adtech, history, apple. Expect a similar wide range in the future as well. You can check all my weekly readings by checking the tag here . You can also get these as a weekly newsletter by subscribing here.





NOTE: The themes are varied, and some links below are affiliate links. Data engineering, adtech, history, apple. Expect a similar wide range in the future as well. You can check all my weekly readings by checking the tag here . You can also get these as a weekly newsletter by subscribing here.
 |
| Photo by Benjamin Wong on Unsplash |
The Launch
And it’s not about a technology product.How I practice at what I do
Working on improvement is a full time job, that you usually need to take during your free time.The Good Employee, a story about how you can explain modern companies with graph theory
This was a weird read. But now I wonder if I can use Prim’s algorithm to improve my decision making?The Washington Post is preparing for post-cookie ad targeting
The cookiepocalypse is coming, and if you work in adtech you should be thinking about it.Dry Stone Walls – Principles of structurally sound construction
Around my hometown (L’Arboç) there’s an abundance of dry stone wall huts, presumedly from around 18th century. Now I know how to build one.Book Review: Impro by Keith Johnstone
You may be aware that I read anything that can improve me in any way. So, Impro is now on my currently reading.Introducing Dagster
Anything that is not Airflow is a win on my book, but I’m not super-thrilled about how Dagster works either.Here Dragons Abound: Iskloft Mountain Style
I have always loved maps and map-drawing, so how to draw fantasy maps is an interesting enough subject on its own.Why Category Theory Matters
I’m ramping up my category theory knowledge lately (and spreading through to sheaves and maybe schemes).Roger Federer as Religious Experience
We’ll miss him (and Rafa Nadal, and Novak Djokovic) when he retires.Did Functional Programming get it wrong? - Noteworthy
I’ve been thinking about “spreadsheets” as in “data and code mixed” lately, specially in terms of category theory, so this post was... close to mind-reading.If you’re playing EVE online you basically already have an MBA
I’ve never been drawn to that game, but given the amount of hours some people give it, it makes total sense.Haskell - An Experience Summary
As part of my categorification, I’m back again at learning Haskell (using Haskell Programming from First Principles). So I’m reading anything reasonably non-technical about Haskell.'These kids are ticking time bombs' -- The threat of youth basketball
The amount of bone and tissue stress a young basketball player has gone through is astonishing.‘I don’t see jeans in my future’: the people who wear complete historical dress – every day
I like that 30s look. I even have a similar hat.Preserving Laptop Stickers on MacBooks - Graham Stevens
Seems too late for my batch of stickers, but I always pick 2 of a kind if possible, now I’m thinking where should I show the duplicates.For 40 Years, Crashing Trains Was One of America’s Favourite Pastimes
Watching things explode has always been fun?Pearls Before Breakfast
Would you recognize genius if it was in front of you?📚 Finite and Infinite Games
I’ve seen many people recommend this book... And I didn’t get it. It was interesting, but not so much as I expected.🎥 Approaching the Yoneda Lemma
Some ways of seeing the Yoneda lemma. I’m still trying to wrap my head categorically, without forgetting anything. I want to be free.Newsletter?
These weekly posts are also available as a newsletter. These days (since RSS went into limbo) most of my regular information comes from several newsletters I’m subscribed to, instead of me going directly to a blog. If this is also your case, subscribe by clicking here.
21/05/2019 - LSP for Python and Scala
If you have have known me for any length of time you'll know I write mostly Python and Scala lately (Rust is getting into the mix slowly). And you should know, I am a heavy
One problem of using
This is why I learnt how to set up GNU global, jump to definition is just too handy. Luckily, the people at Scala Center not only are smart, but also try to improve developer experience, and had been working in a language server for Scala for a while, called metals. I got it working recently, and it's great. You get documentation on hover, error messages, jump to definition. Oh, I forgot to mention, the language server protocol is an invention from Microsoft to standardise how editors handle language completions and all that. They probably introduced it for Visual Studio Code (I actually use it from time to time, it has some remote pair programming capabilities I'll talk someday), but now it's extending across all editors.
After using LSP in emacs for Scala for a while I decided to set it up for Python as well, in preparation for our next PyBCN podcast, about tools we use. I was pretty happy with the completions I was getting, but semantic completions from a language server are usually better. So far, lsp with python is ok. Oh, you'll see screenshots at the end!
You'll need to install the language server. I usually have a high level Python environment with all my tools, for things I am just starting to work on:
After this, some configuration is needed in
You can see how it looks now.
Sadly, inlined documentation doesn't look as good as it should: compare with Scala with metals and lsp-scala:
If you've gotten this far, I share my most interesting weekly readings in tag here . You can also get these as a weekly newsletter by subscribing here.



emacs user. I have been using emacs for close to 15 years, for the past 3 my emacs of choice has been spacemacs. I used to have a very long, customised and complex .emacs and with spacemacs I get a mostly-batteries-included package. That's nice after a while, and I also have gotten really proficient at using evil.One problem of using
emacs is the integration with some languages. If you write Scala, with IntelliJ you get super-fancy completion, refactoring, code analysis, jump-to-definition... Many goodies. In emacs, the best-in-class system used to be ensime. It worked, but it was not really supported for spacemacs (since I'm an old emacs user I could play around that), but the main issue was that my old MacBook was short on memory for running ensime and a lot more. So, I wrote most of my Scala code in hardcode mode. No completion, documentation or jump to definition. This is why I learnt how to set up GNU global, jump to definition is just too handy. Luckily, the people at Scala Center not only are smart, but also try to improve developer experience, and had been working in a language server for Scala for a while, called metals. I got it working recently, and it's great. You get documentation on hover, error messages, jump to definition. Oh, I forgot to mention, the language server protocol is an invention from Microsoft to standardise how editors handle language completions and all that. They probably introduced it for Visual Studio Code (I actually use it from time to time, it has some remote pair programming capabilities I'll talk someday), but now it's extending across all editors.
After using LSP in emacs for Scala for a while I decided to set it up for Python as well, in preparation for our next PyBCN podcast, about tools we use. I was pretty happy with the completions I was getting, but semantic completions from a language server are usually better. So far, lsp with python is ok. Oh, you'll see screenshots at the end!
You'll need to install the language server. I usually have a high level Python environment with all my tools, for things I am just starting to work on:
pyenv virtualenv 3.7.1 tools
pyenv activate 3.7.1/envs/tools
pip install "python-language-server[all]" bpython mypy flake8After this, some configuration is needed in
emacs. Here you can find parts of my configuration, commented. These sit in my dotspacemacs/user-config;; First come the configurations for Scala language server
;; thingies. sbt is the Scala build system.
(use-package scala-mode
:mode "\\.s\\(cala\\|bt\\)$")
(use-package sbt-mode
:commands sbt-start sbt-command
:config
(substitute-key-definition
'minibuffer-complete-word
'self-insert-command
minibuffer-local-completion-map))
;; This is the main mode for LSP
(use-package lsp-mode
:init (setq lsp-prefer-flymake nil)
:ensure t)
;; This makes imenu-lsp-minor-mode available. This minor mode
;; will show a table of contents of methods, classes, variables.
;; You can configure it to be on the left by using `configure`
(add-hook 'lsp-after-open-hook 'lsp-enable-imenu)
;; lsp-ui enables the fancy showing of documentation, error
;; messages and type hints
(use-package lsp-ui
:ensure t
:config
(setq lsp-ui-sideline-ignore-duplicate t)
(add-hook 'lsp-mode-hook 'lsp-ui-mode))
;; company is the best autocompletion system for emacs (probably)
;; and this uses the language server to provide semantic completions
(use-package company-lsp
:commands company-lsp
:config
(push 'company-lsp company-backends))
;; I use pyenv to handle my virtual environments, so when I enable
;; pyenv in a Python buffer, it will trigger lsp. Otherwise, it
;; will use the old systems (I think based on jedi)
(add-hook 'pyenv-mode-hook 'lsp)
;; Flycheck checks your code and helps show alerts from the linter
(use-package flycheck
:init (global-flycheck-mode))
;; Show flake8 errors in lsp-ui
(defun lsp-set-cfg ()
(let ((lsp-cfg `(:pyls (:configurationSources ("flake8")))))
(lsp--set-configuration lsp-cfg)))
;; Activate that after lsp has started
(add-hook 'lsp-after-initialize-hook 'lsp-set-cfg)
;; I like proper fonts for documentation, in this case I use the
;; Inter font. High legibility, small size
(add-hook 'lsp-ui-doc-frame-hook
(lambda (frame _w)
(set-face-attribute 'default frame
:font "Inter"
:height 140)))
;; Configure lsp-scala after Scala file has been opened
(use-package lsp-scala
:after scala-mode
:demand t
:hook (scala-mode . lsp))You can see how it looks now.
 |
| Traditional completion (non-LSP) |
 |
| LSP-powered completion. Way more information! |
 |
| Fancy inlined documentation |
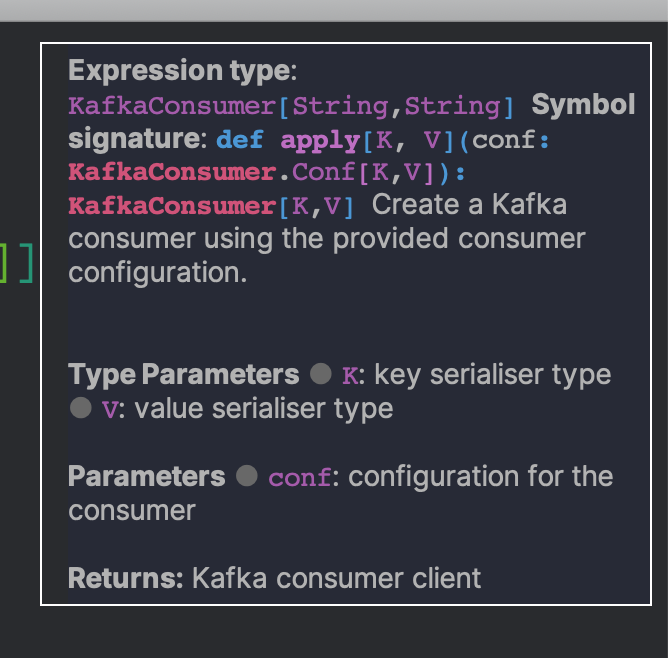 |
| LSP mode in Scala with metals |
If you've gotten this far, I share my most interesting weekly readings in tag here . You can also get these as a weekly newsletter by subscribing here.
19/05/2019 - 2019#13 Readings of the week
NOTE: The themes are varied, and some links below are affiliate links. Functional programming, adtech, history. Expect a similar wide range in the future as well. You can check all my weekly readings by checking the tag here . You can also get these as a weekly newsletter by subscribing here.



 |
| Photo by Mgg Vitchakorn on Unsplash |
Ancient Chinese Buildings Are Held Together With Rice
As everyone who has prepared sticky rice and forgotten to clean the pan quickly knows.'I'd Have These Extremely Graphic Dreams': What It's Like To Work On Ultra-Violent Games
Fatality burnout.The Artistry of China’s Ivory Puzzle Balls
I’ve seen one from really close and they are amazingBristol academic cracks Voynich code
There was a rebuttal of this approach close to 2 years ago, but it still sounds interesting. Also, I’d expect phys.org to be somewhat trustable.Technical Debt? Probably not.
Pay it off. Or not.Scala's Future.successful: Do Not Block Your Future Success
Beware the future!The Functional Scala Concurrency Challenge
Some of the solutions look neat, and there is something to be learnt in the diversity.Technical overview of ads viewability measurement methods
I have always been interested into how ad viewability (if an ad is seen by a user or not) works. Now I know.GraalVM installation and setup on macOS
GraalVM is a new Java runtime and compiler, which is somewhat faster than the normal JDK, and offers some really fancy cross-language options. I had been using RC9 or 10. It was time to update. I usually use Enterprise Edition for anything local, but can switch per-terminal with several aliases I have (j8, j11, jgree and jgrce) in case something breaks or I want to try another.Caire - a content aware image resize library
Seam carving is so cool. I wrote a cropping system once, using PILs Haar cascade based object detection. It works pretty well for automated creation of ads, but seam carving is way better for almost all other cases.🎥 Flare - Optimizing Apache Spark for Scale-Up Architectures and Medium-Size Data
I’m scared this will become a closed source, or business-on-top. Code is not available, but results are awesome. Luckily, the papers are (why the code is not as part of the papers is another question).🎥 helm-edit
I had usedmultiple-cursors (and expand-region) in emacs many times, although I had a hard time making it work properly in spacemacs for a while. helm-edit works better already in spacemacs, so, big win!🎥 Understanding Query Plans and Spark UIs
I knew everything in this video already, but it covers lots. Give it a look.🎥 What the ƒ is a monad
Although focused on Java, it’s very well explained for any language. Of course, if you havedo syntax or for comprehensions, better.📚 The Great Mental Models
The audiobook by Shane Parrish, of FS Blog. It was good, but I expected something longer.📚 The art of thinking in systems
If you have read Donna Meadows Thinking in Systems, this won’t give you anything new. And I’d rather recommend TiS.Newsletter?
These weekly posts are also available as a newsletter. These days (since RSS went into limbo) most of my regular information comes from several newsletters I’m subscribed to, instead of me going directly to a blog. If this is also your case, subscribe by clicking here.
09/05/2019 - gtags (GNU global) in emacs for Scala
 |
| Photo by thom masat on Unsplash |
I looked up what solutions were available, and the only option that seemed good enough was using the classic
ctags/etags/gtags I hadn’t used since my C days.Having a tags implementation can bring an almost-decent jump-to-definition essentially for free: gtags (and the others) work by pre-analysing the data and generating symbol maps which are usually stored as files, the overhead in speed and memory is minimal.
Installing it can get somewhat unintuitive (specially on Mac), since you need very specific settings for it to work with emacs and especially, Scala code.
Start by installing GNU global:
brew install global --with-pygments --with-ctags --with-exuberant-ctagspygments.Aside from this you will need to export the following environment variables:
GTAGSCONF=/usr/local/share/gtags/gtags.conf
GTAGSLABEL=pygmentsggtags-mode. If you use spacemacs, you only need to activate the gtags layer.All this has become moot as soon as metals has reached a usable state: now you can have a really fast language server for Scala, written in Scala with low memory overhead.
27/01/2019 - 2019-3 Readings of the week
NOTE: The themes are varied. Software/data engineering, history, formal systems. Expect a similar wide range in the future as well. You can check all weekly readings by checking the tag here . You can also get these as a weekly newsletter by subscribing here.



Fermentation and Daily Life
I’m not a fan of fermented food, but my girlfriend is. The article is interesting even for me.Why Are Young People Pretending to Love Work?
The “grind and hustle” gets old pretty quick.📚 Specifying Systems
The book for learning TLA+ (and, free to download from the link above). I’m reading it right now, step by step. You can also get a paperback version from Amazon (affiliate link) but it's kind of expensive.The Perils and Pleasures of Bartending in Antarctica
It kind of makes sense.“O Uommibatto”: How the Pre-Raphaelites Became Obsessed with the Wombat
Whomwhat?Why Don’t People Use Formal Methods?
As you may have realized, I’m interested in formal methods and verification. I’m not the only one, and since I now pay more attention to articles on the subject, I find more articles to share. Hillel is the author of Practical TLA+ (affiliate link), the book that finally got me to write specs.The 1859 Carrington Event
The idea of this happening “now” is actually scary.Ask HN: What are your “brain hacks” that help you manage everyday situations?
You may pick up one or two tricks that can be useful.What if the Placebo Effect Isn’t a Trick?
Here, take this sugar pill. You’ll be cured.Kafka at Criteo
Slides from Slideshare. The scale is astounding. Note that the engineering blog at Criteo is top notch, but your adblocker is probably going to give you a hard time reading it.When Rust is safer than Haskell
I’m closer to doing useful stuff in Rust than in Haskell, so it’s always good to know Rust has some nice tricks up its sleeve.Inductive invariants
More TLA+ goodness, from Lorin Hochstein.Spark Barcelona Meetup: Speeding up PySpark with Arrow
This Thursday I’m speaking about how PySpark got faster by using Arrow internally. If you are around Barcelona please join us! Note that the slides for this talk are not up yet!📚 Meditation for Fidgety Skeptics by Dan Harris
(note there are affiliate links in here) This is the follow-up to 10% Happier. MfFS is good, offering a more practical take than the previous one. As books to stand on its own, 10% Happier is better though.📽 10 tips for failing badly at microservices
This is a very fun talk about what you should do if you want to prevent (in an ironic way) your company from moving to a microservices-based architecture. You may get flashbacks to the Simple Sabotage Field Manual from the CIA.Newsletter?
I’m considering converting this into a weekly newsletter in addition to a blog post. These days (since RSS went into limbo) most of my regular information comes from several newsletters I’m subscribed to, instead of me going directly to a blog. If this is also your case, subscribe by clicking here and if enough people join I’ll send these every Sunday night or so.
29/04/2018 - Modifying the agnoster theme for zsh
Even though I have been a long time user of oh-my-zsh on zsh (moved from plain bash to zsh like 10 years ago), I have been very minimal on my use of its theme capabilities. I have used the default theme forever:



robbyrussell. But recently I was showing my friend @craftycoder the tweaks I have on my system (fzf, autojump, etc) and he showed me this theme, agnoster. It had several pieces I liked:- Powerline-style prompt
- Git status
- Virtualenv detection
What did I want to modify?
- Too long branch names. Looks very nice with
masterbut is a bit more troublesome withfeature/SAS-4028/kubernetes/poc - I don’t care that much about the path. Current directory is enough
- Usually I like knowing in which
gitproject I am in better
Path
I played around with several options to make the path look as I would like. I started with the shrink-path Zsh plugin, but I didn’t totally like how it looked. I cobbled together a bit ofawk to get 2 or 3 characters out of each piece of the path instead, it didn’t look much better but was taking much more space. Ended up with just current dir, this is excellent actually.Branch name
Paths at work are of the form{kind}/{ticket number}/{description}. I don’t want to know all the pieces. Kind is any of feature, hotfix (very rarely) or occasionally might be something else. It could be shortened to just a few letters. In general, I like seeing the full ticket number (no specific reason). I don’t need to know the full description, it can be shortened to 4 or 5 characters. Awk to the rescue. I love awk. With it I reduced the branch names to what I wanted, additionally I wrote a small checker that makes Spark’s style pull request naming also be shortened. You can check the awk approach here.Git project
Knowing the project and current folder is everything I need to know. If I need to know more, I justpwd.Error under last command, root, background processing
I don’t like my prompt to change shape. I changed the error reporting to switch colours of the current directory to red. And dropped background processes and root reporting, since I’m never root on my machine, and never run anything in the background unless it needs to be globally.User information
I’m usually pretty sure which user I am, so... Removed it, I prefer a shorter prompt if possible.Some helpers
I added a couple of helpers, reusing some of the code/ideas: jump to Github and jump to JIRA. You can see them in the repository.
15/04/2018 - How does the 'in' keyword work in Python?
A subtitle to this post could be More yak shaving
A few days go I played a bit with a naive implementation of Bloom filters in Python. I wanted to time them against just checking whether a field is in a set/collection. I found something slightly puzzling: it looked like
Instead of reading the documentation I delved into the cpython source. Skipping the documentation was a bad idea, since it is not only pretty comprehensive but explains everything... if you know what you are looking for. But a dive into this big pile of C was more fun. I was also stupid enough to not Google the answer until I was editing this post... This excellent Stack Overflow answer covers more or less what I explain here.
The
First, after we have parsed the code and generated a parse tree from our text, we go to the abstract syntax tree. Converting the string
And now, what does actually
This is inside a function called
So, we are calling this
And now we can see what it does:
This means that, technically, all objects have a field in their defining struct for sequences:
Built-in objects (and likely libraries with C extensions) implement these directly in C, and point its slot to the C method:
Finally, this method looks for a method defined in the class and called
If you have been paying attention you’ll see that we are actually deferring to iterative search in two places: when defining the slot in
As expected, dictionary lookup is fancier. It is a common and known performance improvement in Python to change lists or other sequence-like datatypes for dictionaries, since they show the best performance for most operations. Since internally in Python everything from methods/functions to classes is implemented in one way or another as dictionaries (or reusing the machinery that is built for dictionaries), anything that speeds dictionaries up, speeds the whole of Python code. Of course, dictionary lookup is usually fast no matter the language: hash table lookup in general (leaving aside how collision resolution might be implemented in lookup) is O(1) fast. Note that below we have the macro:
There even is a specialised method for cases when the hash key is known (not sure of the use case, since magic methods are hardcoded in the object structs, maybe it’s used to optimise tighter loops?).
And if you wonder how
And here finishes my exploration of



A few days go I played a bit with a naive implementation of Bloom filters in Python. I wanted to time them against just checking whether a field is in a set/collection. I found something slightly puzzling: it looked like
in worked too fast for smaller lists. And I wondered: maybe small lists are special internally, and allow for really fast lookups? Maybe they have some internal index? This raised the question: how does in find stuff in sequences?Instead of reading the documentation I delved into the cpython source. Skipping the documentation was a bad idea, since it is not only pretty comprehensive but explains everything... if you know what you are looking for. But a dive into this big pile of C was more fun. I was also stupid enough to not Google the answer until I was editing this post... This excellent Stack Overflow answer covers more or less what I explain here.
The
in keyword (defined here) is actually a shorthand for running __contains__ from the target object, you probably know this already. Your class will be able to provide in if you add this magic method, you can read about this in the first chapter of Fluent Python. But tracing this inside cpython is a bit cumbersome and got me diving into interesting pieces of the code. By the way, how the Python compiler works is documented here.First, after we have parsed the code and generated a parse tree from our text, we go to the abstract syntax tree. Converting the string
in as part of some node of Python source in this tree into an In here:And now, what does actually
In do? Well, we need to move forward in the compilation chain, and check compile.c:This is inside a function called
cmpop, which is called when we find the COMPARE_OP opcode. This is the opcode we’d see by disassembling anything running in or == or any other comparison operator (all comparison operators are in the same basket, see here). We can follow the route through ceval.c now:So, we are calling this
PySequence_Contains thingy. A bit more grep and we can find it defined in abstract.c:And now we can see what it does:
- Get a pointer to the sequence’s base sequence methods in the C struct slot
tp_as_sequence - If there is a
sq_containsmethod pointer there, invoke it and return - Otherwise, use iterative search
__contains__? The magic happens on new object/class/type definition: typeobject.c The base object all classes extend from looks like the following struct (from object.h):This means that, technically, all objects have a field in their defining struct for sequences:
tp_as_sequence. This is populated when we define a new class (which internally is known as type) in typeobject.c. Slots are populated from what is essentially a dictionary of methods by invoking fixup_slot_dispatchers. This maps the python name __contains__ to the corresponding slot in the struct, sq_contains and defines which function sets it up, slot_sq_contains:Built-in objects (and likely libraries with C extensions) implement these directly in C, and point its slot to the C method:
Finally, this method looks for a method defined in the class and called
__contains__. If it is None (that is, it is defined and is None), object is not a container, that’s it. If it is not defined (hence the null, and this one is actually puzzling... reduces to it not being provided when defining the class... I think), Python falls back to iterating for search using __iter__ (which is what eventually gets called under PySequence_IterSearch). If this is also not valid or available, an error returns, following a chain of -1 in the method lookups.If you have been paying attention you’ll see that we are actually deferring to iterative search in two places: when defining the slot in
sq_contains but also when invoking PySequence_Contains. I’m not 100% sure about why this is the case, and experimenting with the REPL does not get you very far, since you can never be sure if you are hitting PySequence_Contains -> PY_ITERSEARCH_CONTAINS or PySequence_Contains -> sq_contains -> PY_ITERSEARCH_CONTAINS without changing the messages (and I don’t feel like recompiling Cpython). Weirdly, the second case should be faster since it is going straight for the method via the slot without needing an extra method lookup.As expected, dictionary lookup is fancier. It is a common and known performance improvement in Python to change lists or other sequence-like datatypes for dictionaries, since they show the best performance for most operations. Since internally in Python everything from methods/functions to classes is implemented in one way or another as dictionaries (or reusing the machinery that is built for dictionaries), anything that speeds dictionaries up, speeds the whole of Python code. Of course, dictionary lookup is usually fast no matter the language: hash table lookup in general (leaving aside how collision resolution might be implemented in lookup) is O(1) fast. Note that below we have the macro:
#define PyUnicode_CheckExact(op) (Py_TYPE(op) == &PyUnicode_Type)
There even is a specialised method for cases when the hash key is known (not sure of the use case, since magic methods are hardcoded in the object structs, maybe it’s used to optimise tighter loops?).
And if you wonder how
key in dict works, it is of course by introducing the method in the struct for sequences. The snippet below is from dictobject.c, as the methods above.And here finishes my exploration of
cpython to figure out how in contains. Not sure about you, but I had a lot of fun.
25/03/2018 - Coursier resolution failing with HTTP method 416 in sbt
Or, how I made my first contribution to coursier
I was not happy though. For the next weeks (sounds like a lot, but it was more like 2 commits), every time I had to work on this project I was commenting the import to get it to compile/run/test. Until I was fed up enough to check what the problem was.
So... Maven Central is not able to answer range queries? Some edge case is being hit? And, what are range queries used for? This one is easy, for resuming partial downloads.
The likely culprit was me (or my network) stopping
Fixing it was straightforward (the code base for
To test the functionality I used



[trace] Stack trace suppressed: run last service/*:update for the full output.
[error] (service/*:update) coursier.ResolutionException: 1 download error
[error] Caught java.io.IOException:
Server returned HTTP response code: 416 for URL:
https://repo1.maven.org/maven2/org/graylog2/gelfj/1.1.14/gelfj-1.1.14.jar
(Server returned HTTP response code: 416 for URL:
https://repo1.maven.org/maven2/org/graylog2/gelfj/1.1.14/gelfj-1.1.14.jar)
while downloading
https://repo1.maven.org/maven2/org/graylog2/gelfj/1.1.14/gelfj-1.1.14.jar
sbt dependency resolution around 7 weeks ago. I was in a hurry, so I commented out the offending import (since it was not in the subproject I was working on, so was not needed for the run I was in) sent my commit to the heavens and CircleCI was happy.I was not happy though. For the next weeks (sounds like a lot, but it was more like 2 commits), every time I had to work on this project I was commenting the import to get it to compile/run/test. Until I was fed up enough to check what the problem was.
What is response code 416
This is Range Not Satisfiable. This means that either the file we are requesting does not have this range available: it is shorter, or the range is malformed, or who knows. The expectation should be that under a 416 error, a full request is issued, but this was not the case with Coursier (I created the issue and submitted a PR to fix it, should be fixed in the next release).So... Maven Central is not able to answer range queries? Some edge case is being hit? And, what are range queries used for? This one is easy, for resuming partial downloads.
The likely culprit was me (or my network) stopping
sbt while it was fetching the libraries, at some point in the past… maybe. There is a partial download somewhere. Easy fix: clean up the partial download that is lying there, then update. Problem is, somewhere can be more than one place with coursier. Also, I wasn’t sure where the problem was coming from.What to remove
In my case, I had to remove thecoursier local cache at \~/.coursier/cache because this is where the partial download for gelfj was. But it might have been any of .ivy2/cache or .m2/cache. Maybe, even, sbt cache at .sbt/ . Or the ensime cache.Reproducing, fixing
I managed to reproduce it relatively easily. Open any location in your.coursier/cache/v1 folder containing a JAR file. Move said jar to blah.jar.part. This way, it has full size as a partial download, and the requested range in a partial download request will be invalid (actually this was what was happening in my case: Coursier died just before moving .part to .jar). If you run sbt update under coursier on any project using this JAR, resolution will fail with a 416.Fixing it was straightforward (the code base for
coursier seems easy to search) by adding a check for this return code in the area that resets the connection if the returned headers are not valid.To test the functionality I used
sbt-plugins/publish-local to create a SNAPSHOT build I could set in my .sbt. Once I got the bug manually tested I ran the tests suites. I wanted to add a test, but this seemed untestable under the current suites, so I pushed and waited. The lead maintainer gave me some pointers on how to create a test using the current systems (I got very close but didn’t work in the end), and then, a PR by wisechengyi added several helpers for testing a PR he created in a similar situation, so I could add a test to mine. And done!
02/03/2018 - Using Processing from Scala
Processing is a flexible software sketchbook and a language for learning how to code within the context of the visual arts.
From Processing.org
processing.js something around 2011 (there was a native processing.js application for iOS, I used it for a while on my iPad and iPod Touch). 
But, times have change and I’ve been working with Scala for 2 years already. Since Processing is built on top of Java, using it from Scala should be easy (or doable), but finding details (specially not involving using IntelliJ or other IDEs) is tricky. I could not find anything useful so I had to patch it up from several sources.
These are the steps I had to follow to get it running on Mac OS, with Java 8 and Scala 2.12 (the version of Scala is not that important though, and after all is set in the SBT build).
Clone my sample project
You can find a minimal sample project here. I’m using Spire for its implementation of complex operations (also, I have wanted to try this library for a while), so this comes as an extra dependency in addition to the OpenGL bindings for Java.You can run
sbt update while you do all other steps, since fetching the dependencies can always take a while.This will draw the Mandelbrot set using the Distance Estimation Method. I first found this algorithm in The Beauty of Fractals and have liked ever since. It is the algorithm used for the header on this blog and on my LinkedIn profile. A pity it’s not as easy (or even possible) to derive for entire transcendental functions, otherwise I would have used it for my paper.
It's a straight implementation to show a bit of Processing and have a nice image, but it has no antialiasing, no controls for iterations or parameter tweaking. Zoom and adjustments are automatically picked by a really dumb scaling (it shows as you start zooming) and there is no colour palette (nothing prevents adding it except that it would add complications).
It's not the nicest Scala ever. Processing is based on Java, and to get some things working mutability seems to be the best approach. For now.
Install the native libraries for jogamp
Jogamp is the set of multimedia API bindings for Java (binds to OpenGL, for instance, with the jogl sub-package). For Processing we need to install the native libraries (jnilibs in the case of Mac OS, dlls for Windows, so for other Linux systems) into our Java classpath.To do so, first download the full jogamp 7zipped package from here. On uncompress, move all
jnilibs in the lib/macosx-universal folder to somewhere in your Java library path so Java can find them (or, alternatively, change your path). You can easily look which paths form it by firing a Scala REPL and runningSystem.getProperty("java.library.path")
Download Processing
You need the core library from Processing injar format to use in your builds. Just download the processing app, and get core.jar from the Contents/Java folder in the application bundle. Place it into your lib folder.Although I could add it to the Github project (this core is LGPL), I prefer leaving this as a manual step to make sure anyone trying always has the latest version of Processing.
Ready to go
sbt run
If everything went fine you should now see the following (after some time computing):

And, if you click randomly a few times

You can also try to find the magical command that gets you a coloured gradient

14/02/2018 - ClassNotFoundException for Akka logging
A few months ago I stumbled into the problem of Akka logging, specifically ClassNotFoundException when using akka.event.slf4j.Slf4jLoggingFilter, just by following the details of the Logging - SL4J section of Akka documentation. Of course, the error source is obvious in hindsight, but in the moment the fact that this was a multiproject build with several dependency paths made me miss a crucial reason for longer than I want to admit:
YOU NEED TO ADD THE SL4J IMPORT IF YOU WANT TO USE SL4J FOR LOGGING!Add this to your dependencies (I'm assuming you have a val for akkaVersion to DRY):
"com.typesafe.akka" %% "akka-slf4j" % akkaVersion
 |
| FACEPALM (Picard styled, but more hair) |
07/02/2018 - Scala eXchange 2017
Almost two months ago (time sure flies) I attended for the second time the conference Scala eXchange, one of the largest Scala conferences in the world, and which happens to be 1 tube stop from the office you can find me from time to time in London. Also happens to be an excellent conference, and I’m repeating next year (yes, I already got my tickets).
For those who don’t know, Scala eXchange is a 2-day (plus an unconference day) conference in central London, bringing most of the library developers you love to talk about cool stuff.
I got away with a bit better understanding of the relationship of the vague notions I remember from CT (universal properties/objects, final objects, etc) with type theory. All in all, very interesting and a good start.

Be sure to check his company’s (SoftwareMill) blog for a wealth of interesting posts. As well as subscribe to ScalaTimes, which they curate weekly.
I had already seen Daniela’s talk (was on the same slot) A pragmatic introduction to Category Theory at Scala World earlier in the year (and, IIRC with longer time so it was almost a workshop, enjoy the video) so I skipped it. But can recommend, was excellent.
Well, I attended what I think were the coolest: how to actually use Akka Typed, with Heiko and a tour of typelevel libraries and how type classes help in the implementation with Travis Brown. They were oh-so-interesting.
Next year, again and more.
For those who don’t know, Scala eXchange is a 2-day (plus an unconference day) conference in central London, bringing most of the library developers you love to talk about cool stuff.
 |
| Scala time! |
Keynote: The Maths Behind Types with Bartosz Milewski
We started with the big category theory guy. In case you don’t know, Bartosz is the author of the widely loved series of videos on Category Theory for Programmers. Haven’t watched them yet (I don’t have fond memories of Category Theory when I was studying abstract algebra), and from what I heard from people who have, I had the luxury of seeing a short intro to almost half of the series in just a conference session.I got away with a bit better understanding of the relationship of the vague notions I remember from CT (universal properties/objects, final objects, etc) with type theory. All in all, very interesting and a good start.
 |
| Beware! There's a functor behind you! |
Coffe break!
I caught up with the Scala Madrid gang, since they had a stand to promote the meetup. Got a free copy of Dave Gurnell and Noel Welsh Advanced Scala with Cats at the Underscore booth and drank a lot of coffee. I suspect I also stumbled on Jon Pretty and caught up on what he was going to present, but might have actually happened a few coffees later.
Free Monad or Tagless Final? How not to commit to a monad too early by Adam Warski
This was the first time I saw Adam presenting, and was well worth it. My knowledge of tagless final encoding is... shallow, to say the least (and not like my knowledge of free is excellent, but is better) and I left this talk feeling like I learnt a lot. The best way to leave a talk, I think. I also found later that Pere has a comparison of them, also adding the Eff monad to the mix.Be sure to check his company’s (SoftwareMill) blog for a wealth of interesting posts. As well as subscribe to ScalaTimes, which they curate weekly.
 |
| ♬ So Tagless can't you see, I want to break Free ♬ |
Farewell Any => Unit, Welcome Akka Typed! with Heiko Seeberger
I had read stuff by Heiko (for instance, a post on using akka-testkit), and had started having a look at the new typed APIs, but seeing it live-coded by the person who wrote a big part of it is priceless. Now, I need to rewrite my unfinished, unpublished ad server in akka-typed!I had already seen Daniela’s talk (was on the same slot) A pragmatic introduction to Category Theory at Scala World earlier in the year (and, IIRC with longer time so it was almost a workshop, enjoy the video) so I skipped it. But can recommend, was excellent.
 |
| To Akka or not to Akka... Actually, there's no question |
Lunch break
Had lunch with a Scala friend (hi there Carlos!) while explaining which talks I attended and exchanging impressions on the ones he attended. Also discussing freelancing/contracting, situation in Spain… Standard stuff. |
| Meow-some |
Keynote: Architectural patterns in building modular domain models with Debasish Ghosh
It may have been my usual after-lunch sleepiness, but I didn’t enjoy this talk, even if it seemed interesting overall. Might need to rewatch the video to get a second impression.Shapeless is dead! Long live shapeless with Miles Sabin
This was a bit too deep into the internals of shapeless, but Miles is a great speaker so it was quite fun, even if I didn’t get a lot of mileage out of it (yet). |
| Turning the problem around? |
Introduction to Freestyle and Freestyle RPC with Raul Rajá
After getting a better grasp on the free vs tagless dichotomy earlier in the day, I got to enjoy Raul’s presentation on the library he has written with the other folks at 47 Degrees (they are also the organisers of LambdaWorld and LXScala and maybe others). The gist of this library, don’t bother with free or tagless: use freestyle and you can switch from one to the other as you see fit with ease. |
| He walked around as I was shooting... |
Lightning sessions: Optic algebras
This is the only talk I remember, by Jesus Lopez. It was very interesting, but would love to see a full talk on it. I got into the wrong room for the second lightning, and chose wrongly for the third, so won’t even mention.Keynote: The Magic behind Spark with Holden Karau
I’ve had the pleasure of hearing Holden speak something like 6 times already, and she always delivers fun talks. I mostly knew this one, since it was a Scalafication of the keynote she gave on PyData Barcelona 2017 (which focused on the Python side of things, you’ll also see me introducing her first time in the morning, by surprise, before coffee…). You won’t see garden gnomes the same after this talk. |
| Take the red pill |
Freestyle, Free and Tagless: Separation of concerns on steroids with Michał Płachta
This one was mind blowing, enjoyed a lot Michał ’s style. After the warmup on free/tagless/freestyle the day before, I finally got the gist of why we bother with all these programs-as-data-kind-of-functional-encodings. Ticked for several rewatches. You can find the slides here. |
| But, which is the Good, the Bad, the Ugly, Michał? |
Building scalable, back pressured services with Akka, with Christopher Batey
This was an interesting, technical talk about services, TCP and backpressure. A bit too close to metal for what I do currently, but good to be aware of. Also, Christopher gave an excellent presentation, first time I’ve seen him, will repeat.Impromptu: Using dependent types to build a better API for async call graphs with Jon Pretty
I had seen a previous version of this talk at the London Scala User Group meetup, and understood nothing. This time though I got it (not sure if Jon did anything magical with the talk or it was me knowing more), and it has gotten me thinking about similar, graph-related problems and the approach taken (use the types, Luke!) Also, Heiko raised an issue in the repository (since, the code fits in a slide!) and I wrote the small PR to address it. Now I want to do something more useful for the library than that though! |
| Standing room for Jon! |
A reactive database of facts with Peter Brachwitz
I wasn’t overly interested in any of the talks in this slot, so went with this, somehow “database of facts� in my head sounded like Prolog, which made it interesting. It was not (for me), it was more like how to access Datomic with Scala/Akka and doing it properly. Not specially useful for me, but probably is for someone else.???
I sincerely don’t remember which talk I attended in this block. I’m pretty sure it was not Peter Hilton’s How to name things, since I saw that one last year (was great). It might have been Refinement types in practice with Peter Mortier, but don’t remember anything except vaguely mentioning refined types to a coworker for an API we have. Okay, I just checked the video and definitely it was Peter’s. You can find the slides here.Keynote: Composing programs by Rúnar Bjarnason
Coauthor of The Red Book of Scala (beware, affiliate link), and an excellent explainer. This was an outstanding close to a very categorical conference. Even though I’m a mathematician, my working knowledge of category theory has improved 100x after learning Scala and seeing how my colleagues here approach problems in a very categorical, functional, typed way of seeing the world. |
| Wat |
Unconference
Last year we had a PR hackathon, where together with Carlos we contributed a WIP for regexes to scala-native. This year we had more of a workshop/live coding event, where we could choose among subjects. I don’t remember all of them. Raul was there for Freestyle (missed on this one). There was one about writing stuff for Minecraft in Scala...Well, I attended what I think were the coolest: how to actually use Akka Typed, with Heiko and a tour of typelevel libraries and how type classes help in the implementation with Travis Brown. They were oh-so-interesting.
Next year, again and more.
31/08/2017 - Solta
De totes les illes que hi ha prop de Split vam decidir buscar la tranquil·litat de Solta. Hvar i Brac ens van semblar massa turístiques, i per tant massa gent. En una hora de vaixell van arribar a Rogac, a … Continua llegint →
30/08/2017 - Split
Vam arribar de Zadar a Split per la tarda, i ens vam dedicar una estona a posar ordre a la maleta, bàsicament a rentar roba, que ja se’ns havia acabat, i comprar alguna cosa de menjar per aquests tres dies … Continua llegint →
29/08/2017 - Trogir
L’endemà d’arribar a Split vam decidir arribar-nos a Trogir, una ciutat Patrimoni Mundial de la Humanitat. El casc antic és una illa de no més d’1 km2 accessible per dos ponts. El casc antic és tot de pedra blanca, igual … Continua llegint →
24/08/2017 - Zagreb
Amb la incertesa de quanta estona hauríem d’estar fent cua a l’aeroport, ens vam llevar ben d’hora i a mes cinc ja hi érem, per sort, amb una nena de menys de cinc anys passes per uns controls de seguretat … Continua llegint →
20/08/2017 - Change the parameters of a docker container without knowing the docker run command used
I'm not sure how useful this Docker "trick" is, since it happens in a very niche situation.
At work, we have several instances running a suite of Docker containers, with some non-trivial amount of environment variables, port configurations, volumes and links among them. This is set up really easily using
The problem arises when you are logged in on one of the machines and you want to change (or add) one parameter to one of the currently running containers. Re-running the
We jokingly call it the Indy swap

It's quite easy, and is best described using a checklist to avoid messing up.
Steps 5-7 are the actual Indy swap, if we are not fast enough the healthcheks in our elastic load balancers will mark the instance as failing and stop it. Yes, we could disable the check while we do this, but where's the thrill, then?
By the way, the file in 4 will be a JSON file with the settings of the container. Any saved edit needs to be done with the docker service closed (since the file is in use otherwise). The format of adding ports, volumes or links is pretty self-explanatory as long as you have already a port, link or volume set up in the instance. Otherwise, check the configuration of any other running container having that. I suggest opening it in 4 with the editor already so you can up-arrow just after stopping the service without needing to find it, and also having planned the changes beforehand (or having done them in a
Oh, and don't do this in production. Oh, of course you won't because you are not using Docker in production, are you?
At work, we have several instances running a suite of Docker containers, with some non-trivial amount of environment variables, port configurations, volumes and links among them. This is set up really easily using
ansible: writing link/port/volume mappings in ansible (using the docker, container or docker-container modules, depending how long ago we set it up). The syntax is similar to docker-compose, but scripted for ansible.The problem arises when you are logged in on one of the machines and you want to change (or add) one parameter to one of the currently running containers. Re-running the
ansible script in full is not always an option (for reasons I don't want to get into), so up until now we had to painfully rewrite the docker run command from the ansible set up, by hand. Which is terribly error prone. And a pain. And in general very much a process you don't want to follow, ever. We were very close to writing a short python script to convert the yaml specifications from python into docker run commands when we found out a relatively less painful way of doing it.We jokingly call it the Indy swap

It's quite easy, and is best described using a checklist to avoid messing up.
- First, you figure out what you want to do. For instance, map a port
- Change to super-user
- Get the container id from
docker ps - Use your favourite remote editor to inspect the file
/var/lib/docker/containers/{container_id}/config.jsonto figure out what you need to add service docker stop- Edit the file in step 4 to add/remove any extra setting
service docker start- VoilÃ
Steps 5-7 are the actual Indy swap, if we are not fast enough the healthcheks in our elastic load balancers will mark the instance as failing and stop it. Yes, we could disable the check while we do this, but where's the thrill, then?
By the way, the file in 4 will be a JSON file with the settings of the container. Any saved edit needs to be done with the docker service closed (since the file is in use otherwise). The format of adding ports, volumes or links is pretty self-explanatory as long as you have already a port, link or volume set up in the instance. Otherwise, check the configuration of any other running container having that. I suggest opening it in 4 with the editor already so you can up-arrow just after stopping the service without needing to find it, and also having planned the changes beforehand (or having done them in a
config.json1 you then swap)Oh, and don't do this in production. Oh, of course you won't because you are not using Docker in production, are you?
25/06/2017 -
Preparant la ruta … propera parada … Croàcia! “Full of life”kFiled under: 2017 Croàcia Tagged: Croàcia
07/05/2017 - Shading dependencies with sbt-assembly (in particular, shapeless in Spark 2.1.0)
A few weeks ago I needed to parse configuration files in Scala for a Spark project and decided to use PureConfig. It is incredibly lean to use, needing minimal boilerplate. I recommend you check it out (give also a look at CaseClassy, which I haven't had time to test yet).
Everything seemed straightforward enough, and I got it working pretty quickly (as in, it compiled properly). The surprise?
spark-submit failed with a conflict with Shapeless (lacking a witness). This is due to Spark 2.1.0 needing Breeze, which in turn needs Shapeless 2.0.0 (which is pretty old). Problem is, Spark's required library prevented PureConfig from pulling the correct version. D'oh!There is an easy fix, though, if you are using sbt-assembly you can shade dependencies, by adding something like the following to your
assembly.sbt file:assemblyShadeRules in assembly := Seq(ShadeRule.rename("shapeless.**" -> "new_shapeless.@1").inAll)
11/09/2016 - More emacs configuration tweaks (multiple-cursor on click, minimap, code folding, ensime eval overlays)
At Affectv we use a wide range of editors: Sublime, Atom, Emacs, Pycharm, IntelliJ... Actually only two people use the same editor! As such, from time to time I see things in other people's editors that I would like to have as well. So, yesterday I decided to improve on some configuration settings on Spacemacs.
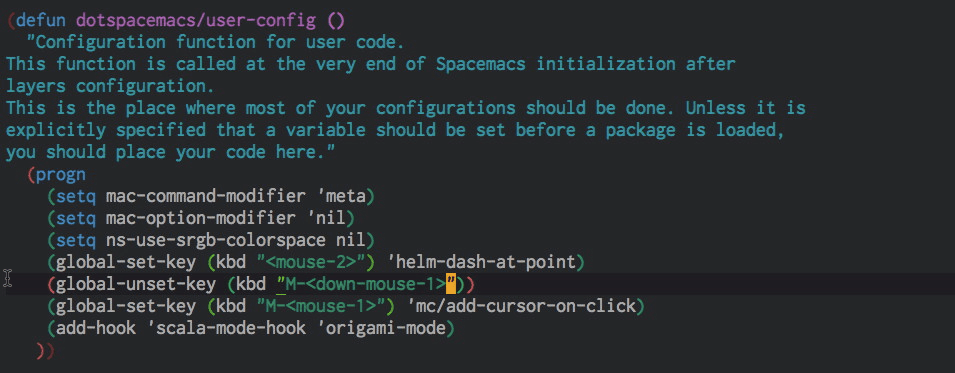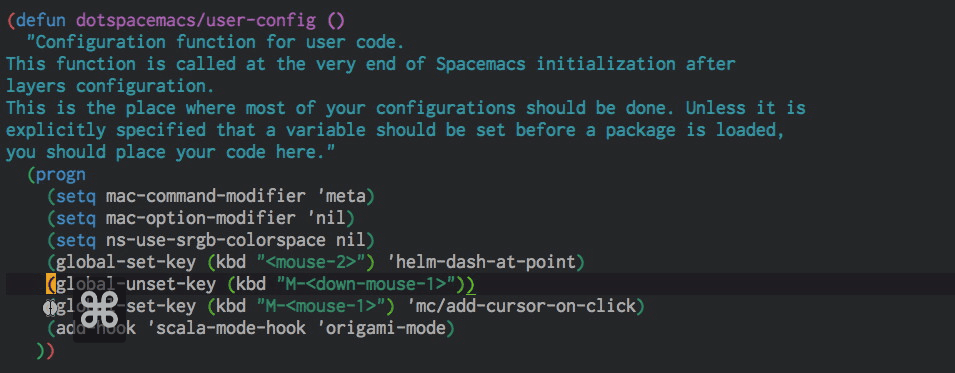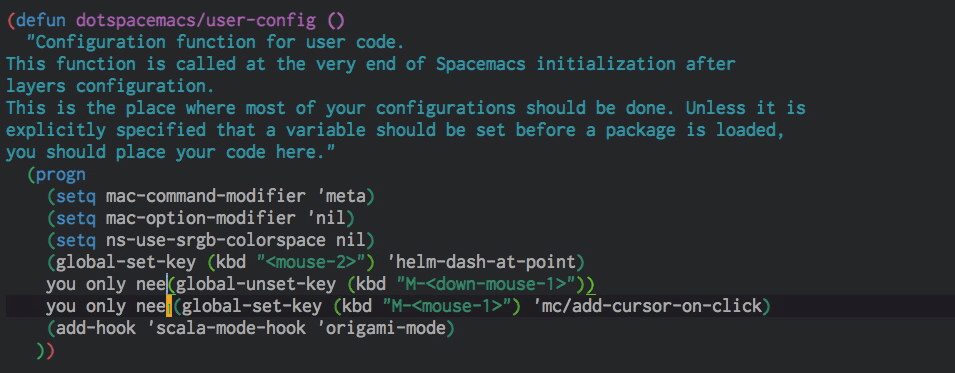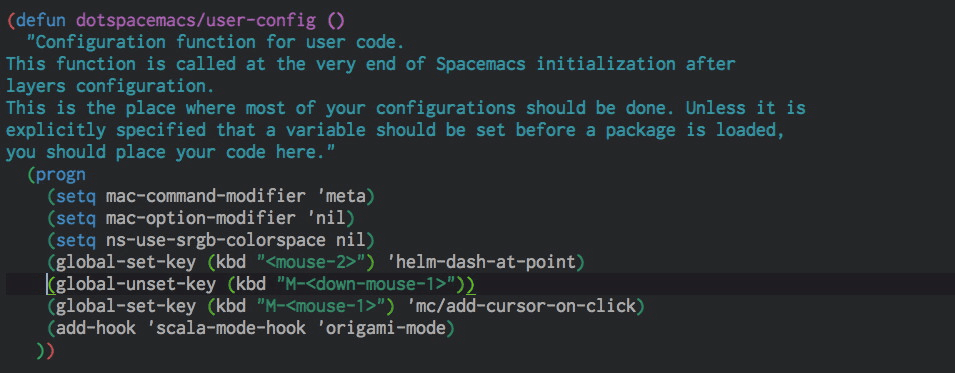
Click for multiple-cursors
I saw this on Jordi's Sublime, and it is much more comfortable than using more-like-this or similar helper functions, even if I need to use the trackpad to do so. After all, a multi-cursor edit (proper edit, not as a substitute for a macro) is rare enough that I can tolerate leaving the home row. Easy enough to configure thanks to Magnar Sveen.
(global-unset-key (kbd "M-<down-mouse-1>"))
(global-set-key (kbd "M-<mouse-1>") 'mc/add-cursor-on-click)
Minimap
Also from Sublime, I had this on my old emacs setup. As simple as adding minimap to the list of additional packages and configuring its property group. See animation below.
dotspacemacs-additional-packages '(helm-dash key-chord pig-mode mmm-mode minimap origami ansible)
Folding
I have always loved how clean vim's folding works, and how Sublime has this nice folding. Then I found origami-mode and my emacs-life was complete. I tweaked a little the folding functions so that minimap was updated on fold (for some reason it is not, I guess minimap is tied to the "modified" hook or similar). I bound
z and Z (and A-z which maps to æ in Colemak) to the basic fold operations.(eval-after-load 'origami
'(progn
(defun rb-show-only (buffer point)
(interactive (list (current-buffer) (point)))
(progn (origami-show-only-node buffer point)
(minimap-new-minimap)))
(defun rb-toggle-rec (buffer point)
(interactive (list (current-buffer) (point)))
(progn (origami-recursively-toggle-node buffer point)
(minimap-new-minimap)))
(define-key evil-normal-state-map "æ" 'rb-show-only)
(define-key evil-normal-state-map "Z" 'origami-toggle-node)
(define-key evil-visual-state-map "Z" 'origami-toggle-node)
(define-key evil-insert-state-map "C-Z" 'origami-toggle-node)
(define-key evil-normal-state-map "z" 'rb-toggle-rec)
(define-key evil-visual-state-map "z" 'rb-toggle-rec)
(define-key evil-insert-state-map "C-z" 'rb-toggle-rec)
)))
For some reason just advising the functions with after didn't work, this is not great but does work. I left the Z bindings as they are, since I have not used them yet, and will probably delete them if I keep not using them.
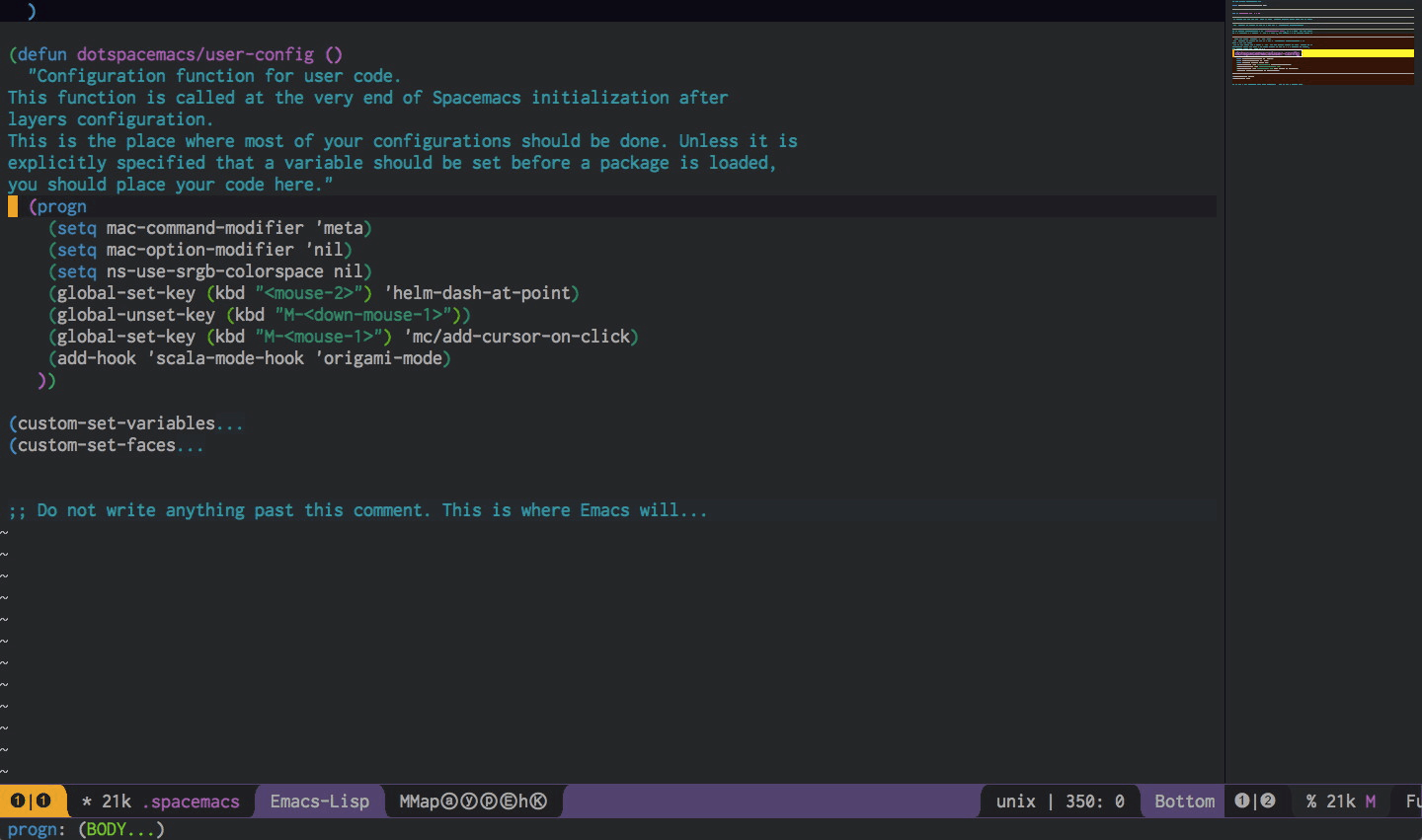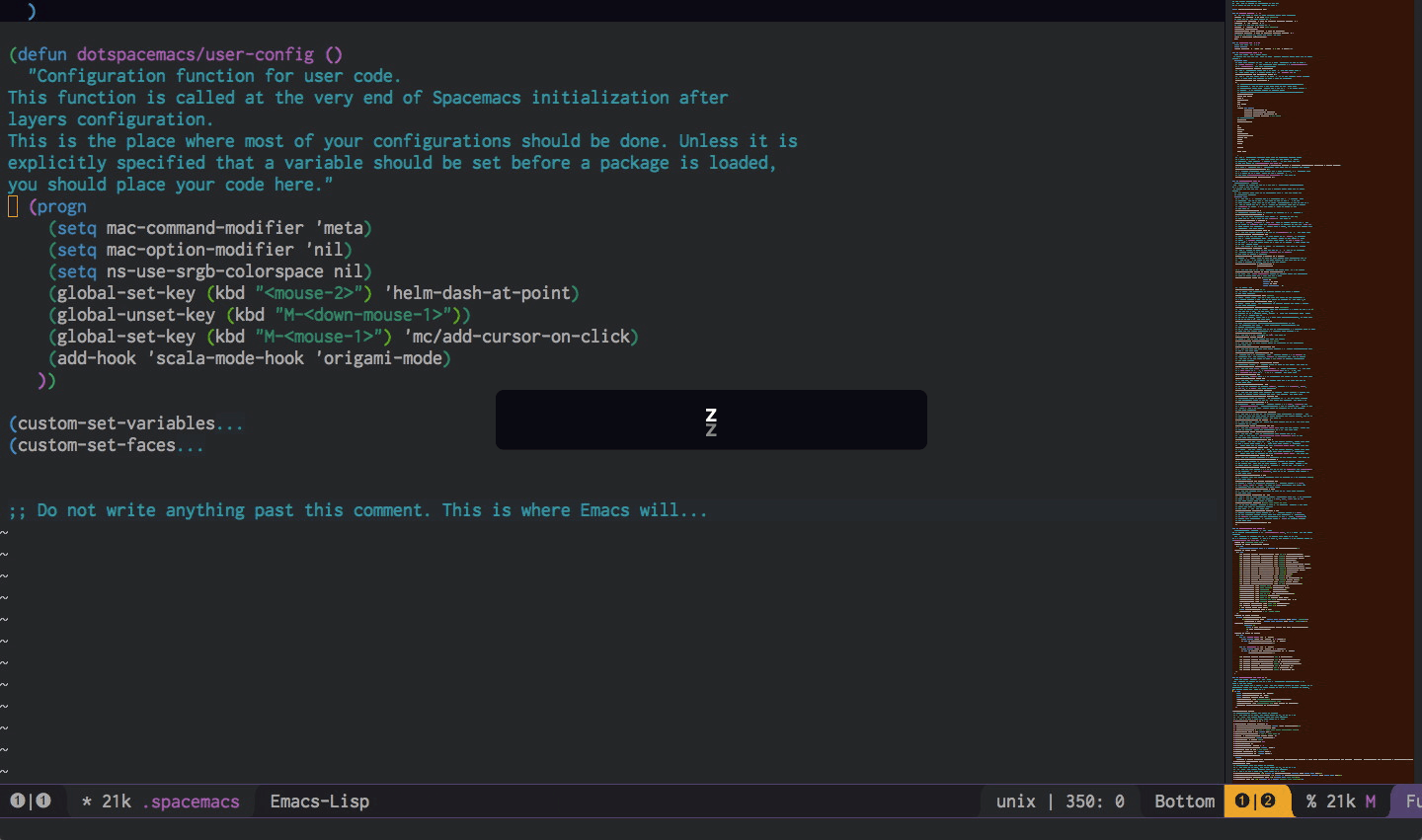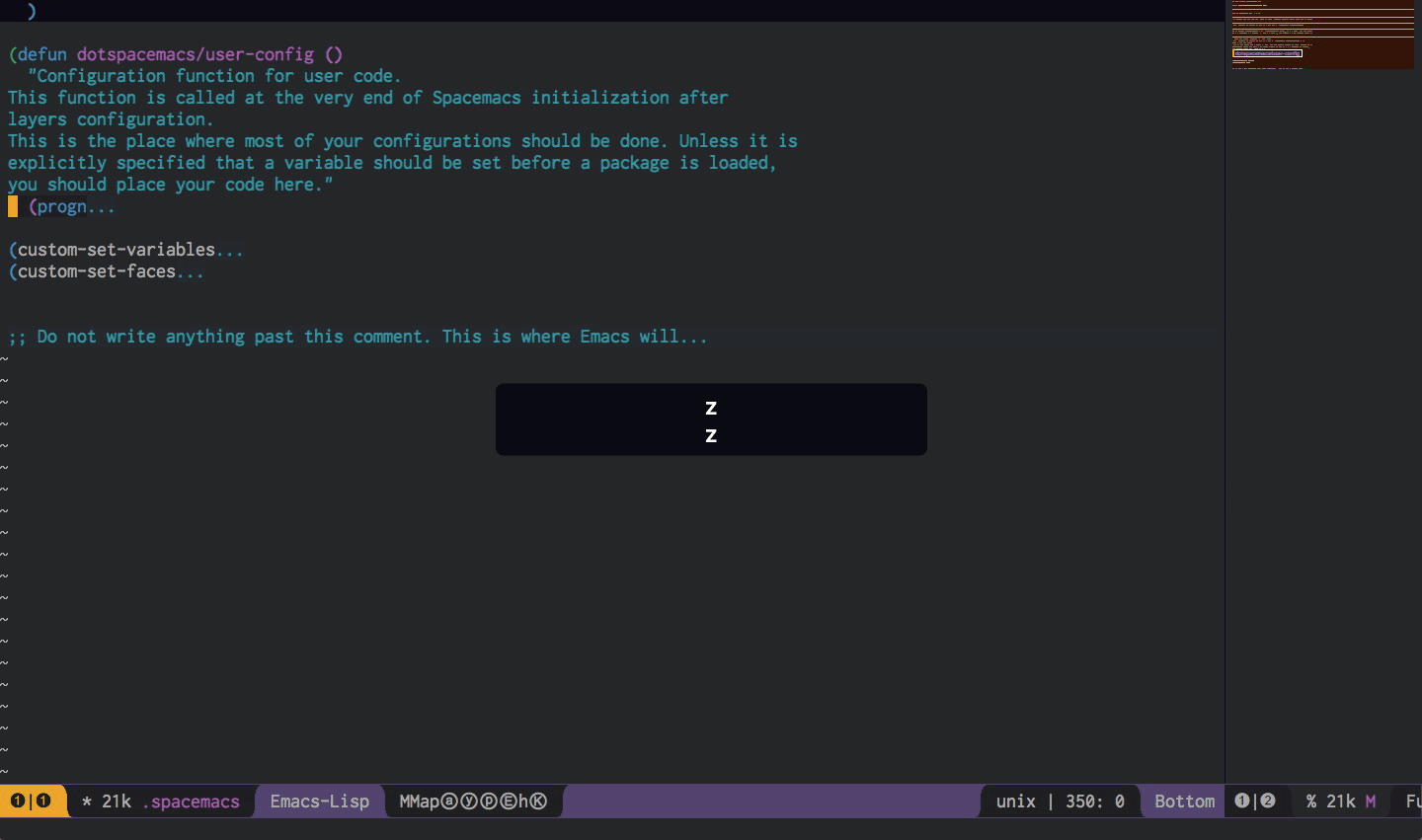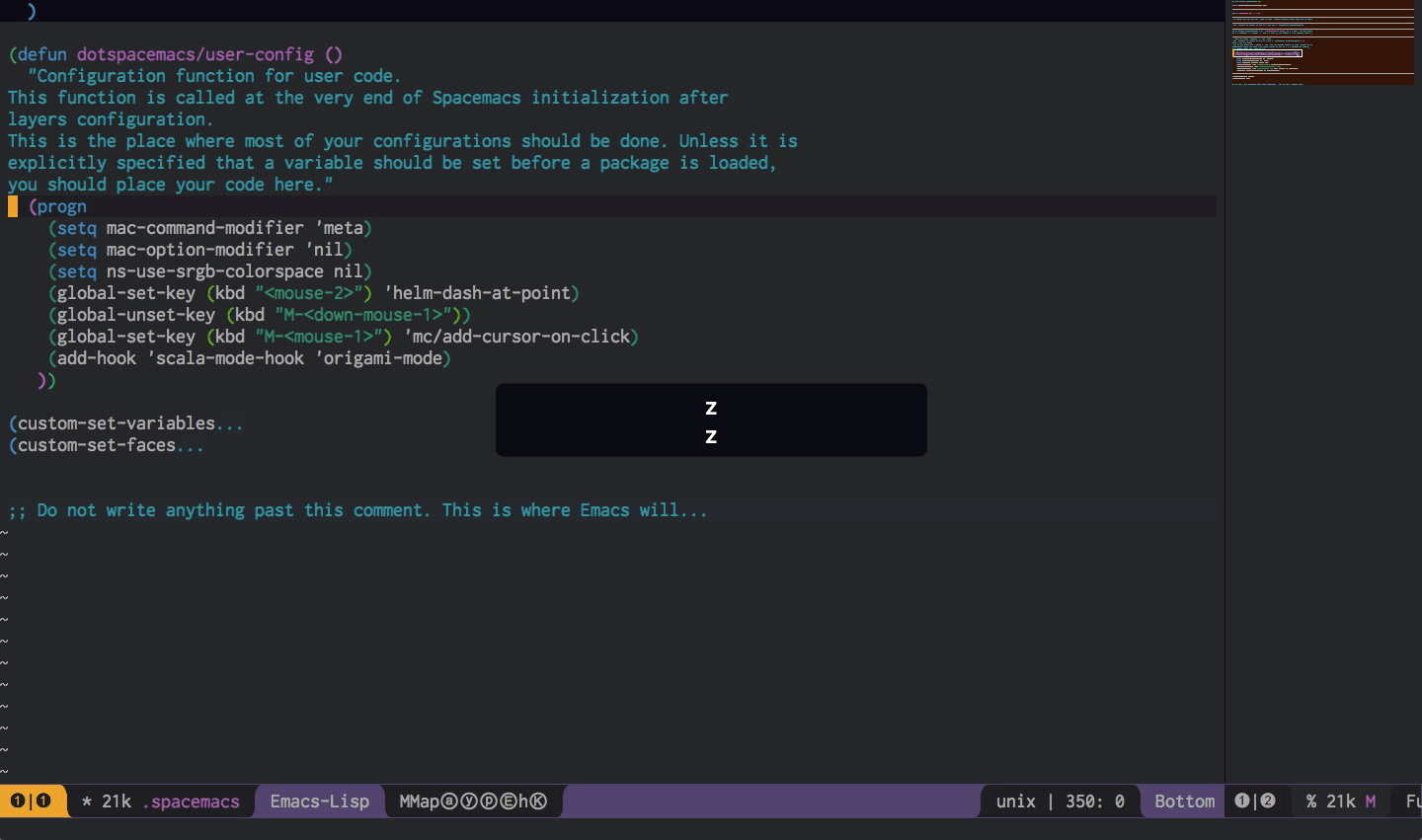
Execution overlays in Ensime (Scala)
I saw this for Cider in the emacs church meeting from August, and heard @fommil (I think it was him) mention that it was coming to ensime. And indeed it was. And it's easy enough to use
C-c C-v C-r (thing of it as extended command, eval, region to remember), given an open inferior Scala interpreter. Symbol prettify does not apply to overlays, so you need to customise the arrow used therein.
28/08/2016 - Narbona
L’últim dia de viatge el vam passar a Narbona. Després de deixar les coses a l’apartament que havíem llogat, molt cèntric, a la bonica plaça de les 4 fonts, vam fer una bona passejada pel casc històric de la ciutat: … Continua llegint →
27/08/2016 - Millau
De ruta cap a Albi ens hem aturat a Roquefort-sur-Soulzon, a visitar les caves de Roquefort, tot i que la visita és exclusivament en francès, ens van donar un resum en català. Una visita força interessant … a deu graus! … Continua llegint →





